Zilele trecute circula pe social media un exemplu de eroare a ChatGPT la următoarea problemă:
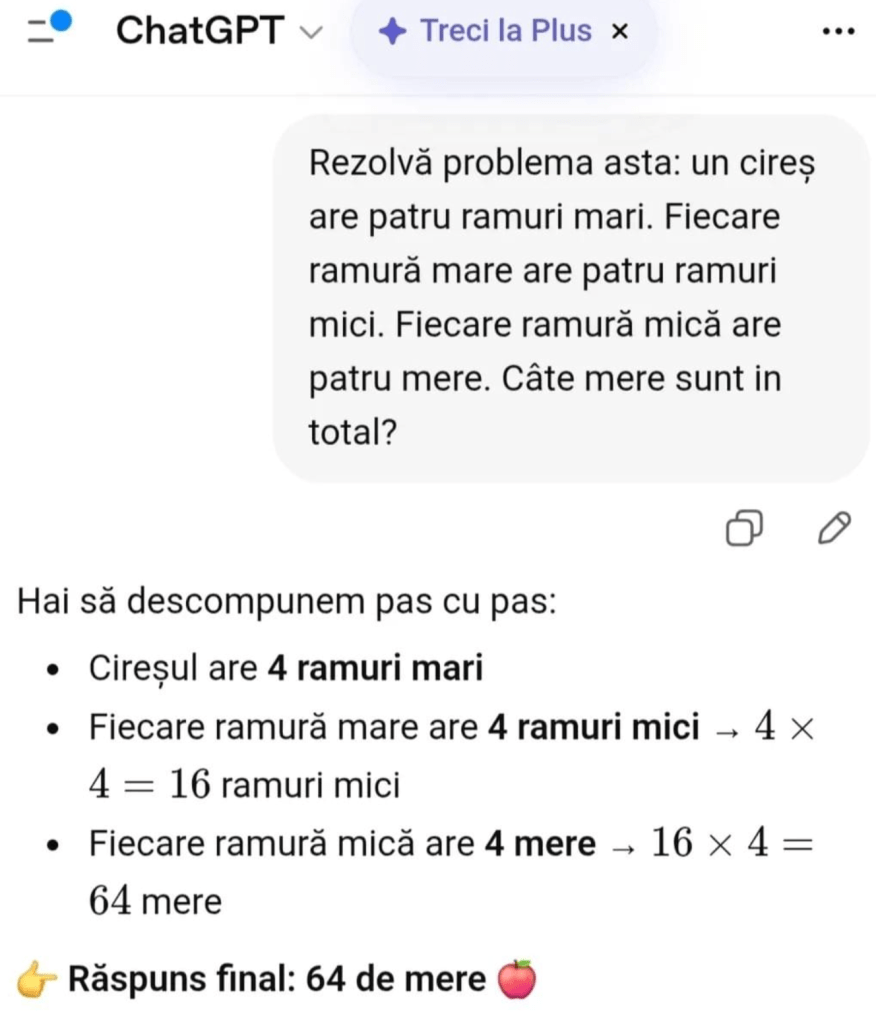
Am verificat și eu, atât cu ChatGPT (OpenAI), cât și cu Claude (Anthropic) și a ieșit că:
- ChatGPT face, într-adevăr, această greșeală;
- Claude însă, și-a dat seama de eroarea ascunsă în problemă:

De ce a căzut ChatGPT în capcană?
ChatGPT nu a „citit” problema, ci doar a recunoscut un tipar familiar (ramuri, fructe, înmulțire) și l-a executat automat. Detaliul absurd (mere în cireș) a trecut neobservat pentru că nu conta pentru tipar.
De ce nu a căzut Claude în capcană?
L-am întrebat chiar pe el și iată ce a „zis”:
De ce eu am prins capcana?
Sincer, nu știu sigur. Poate că în datele mele de antrenament existau exemple similare de capcane logice. Sau poate a fost o chestie de șansă.
Concluzia importantă:
Nici un model de limbaj, inclusiv eu, nu este imun la astfel de capcane. Data viitoare s-ar putea să fie invers — eu să cad, iar ChatGPT să prindă. Aceste teste sunt utile tocmai pentru că ne reamintesc că LLM-urile nu „înțeleg” cu adevărat, ci recunosc tipare.
De ce contează asta pentru noi, avocații?
Pentru că un LLM (Large Language Model) va citi un contract și va recunoaște tipare juridice familiare. Va genera clauze care arată corect, care sună corect, dar care pot fi fundamental greșite în context.
Va pune mere în cireș. Și le va prezenta cu toată încrederea.
Trebuie să reținem deci că A.I.-ul deși e util, nu e colegul de cabinet pe care ne putem baza orbește.
Folosiți-l pentru viteză, pentru primul draft, pentru cercetare preliminară.
Verificarea finală trebuie însă să rămână la noi, pentru că doar noi înțelegem contextul juridic. A.I-ul doar îl imită.
Explicați asta și clienților voștri, aceia care vă verifică cu ChatGPT sau Claude.
